
As we navigate through the evolving landscape of documentation and data processing, we're witnessing a significant shift from traditional rule-based systems to the more dynamic and intelligent approach that is based on the main principle of machine learning—learning from data to perform tasks without being explicitly programmed.
This shift is particularly evident in the rapidly growing field of Intelligent Document Processing (IDP), and this transition is hardly surprising given the relentless increase in data volume, the rapid advancement and refinement of AI algorithms, and the gradual move from structured to unstructured data formats.
Here, we will explore several IDP issues and questions that have surfaced through interactions with our clients at Binariks. We'll explore the nature of these issues, the challenges they present, and why achieving a fully automated IDP system remains an elusive goal.
Furthermore, we will investigate the array of tools and approaches tailored to specific scenarios, thereby laying a foundation for a deeper understanding of IDP without diving into the technical depths of its implementation.
Decoding IDP: Revealing key patterns and challenges
One of the key revelations of the digital era has been the unique advantages of automating business processes. Companies that replaced manual processes with automation, wholly or through minimal viable replacements, have gained substantial competitive edges, significantly accelerating their operations over their competitors.
Document processing and analysis are critical for such enhancement, particularly in sectors like insurance, fintech, and healthcare, which often rely on physical document copies. The capability to expedite document data interpretation can exponentially amplify the business's efficiency, given the vast quantities of documents handled, leading to remarkable time and cost savings.
While there are lots of tasks that may arise in the field of IDP, the Binariks team, through its engagement across various industries, has identified common patterns and challenges in document processing :
- Understanding document content
- Entity recognition
- Document classification and tagging
- Document layout parsing
Understanding document content
The shift from traditional systems to those empowered by large language models (LLMs), an essential branch of generative AI , marks a significant advancement in how we handle document content and use AI that can understand and decide based on it.
Where old systems required meticulous and often manual data indexing for retrieval—prone to errors and demanding regular updates—LLMs offer a simplified, more dynamic approach. Today, specialized services can provide accurate answers to queries about documents without needing the user to understand the document's content, thereby streamlining the process significantly.
The other widely required task that falls under this category and may be used in conjunction with other intelligent mechanisms is document summarization—a particularly useful ability of LLMs that helps to grasp the very heart of large volumes of text.
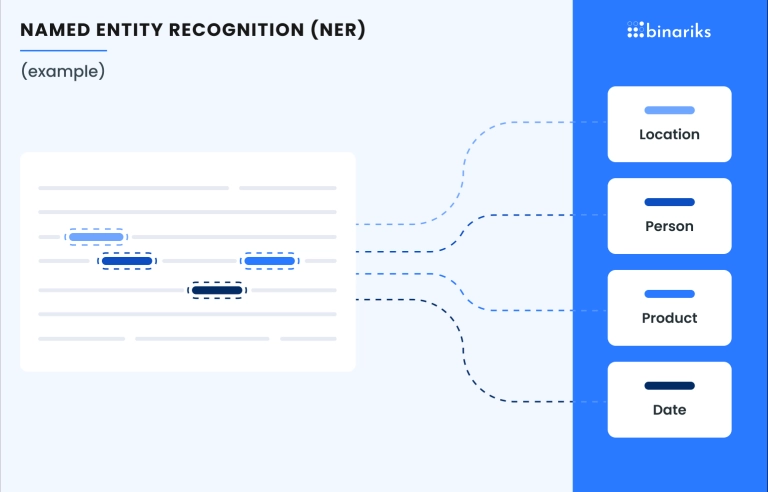
Entity recognition
A prevalent challenge is the need to extract specific data fields from documents for analysis or further processing. The diversity of document formats and contexts necessitates models trained to recognize these entities accurately across different scenarios.
Techniques like Named Entity Recognition (NER) or its spatial enhancement facilitate this process, enhancing both efficiency and accuracy.
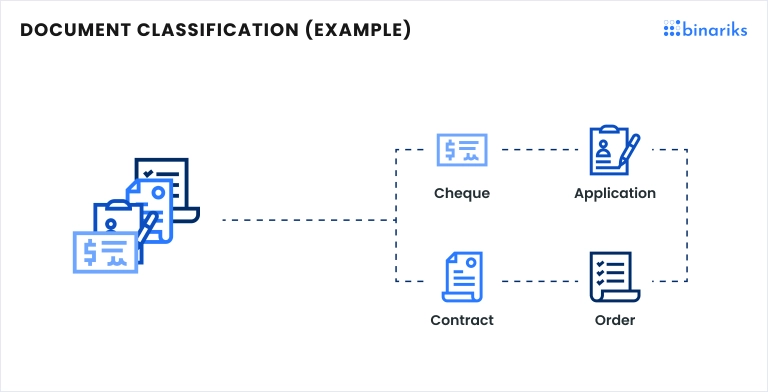
Document classification, tagging, and labeling
The necessity for document categorization based on their content is another area where traditional rule-based engines fall short, often leading to inaccuracies.
Machine Learning (ML) algorithms, trained on specific datasets and capable of ongoing learning and adaptation , combined with the LLMs promise a solution. They significantly reduce errors, streamline document handling, and adapt over time to improve accuracy. These tasks may be considered as a specific case of understanding document content.
Document layout parsing
In contexts where referencing original text is crucial, such as quoting, LLMs may face challenges due to their ability to generate responses that may seem off-topic and their ability to hallucinate. Simple PDF text parsing or utilization of optical character recognition (OCR) to read it line-by-line may lose or even spoil the context of the document.
Document layout parsing, or breaking down documents into smaller, contextually, and logically connected manageable units (like paragraphs, columns, lists, headings, and subheadings), becomes essential. This process enables precise location and highlighting of text that is contextually connected within documents in response to queries. It usually involves different ML models to handle various tasks that form the final solution.
How does it all play out?
These IDP tasks differ, like document classification or content understanding, to answer the question "What is this document about?" while others, like entity recognition and layout parsing, utilize sophisticated techniques to extract valuable information from the document so it can be used later. This should give you the intuition that IDP is a multifaceted task and the amount of tooling you use heavily depends on your business case.
Someone may argue that lots of other tasks in the field of IDP may be added to this list, but the core idea here is that most of the real-world cases we face here at Binariks require multiple tasks to be resolved in order to tackle the client's problem in a systematic way, as we have already mentioned in the previous paragraph. To illustrate this, let's consider a simplified example.
Imagine trying to build a chatbot solution that can provide answers based on information from some specific document database, which is a common application of generative AI nowadays. One approach often used for this scenario is the Retrieval Augmented Generation.
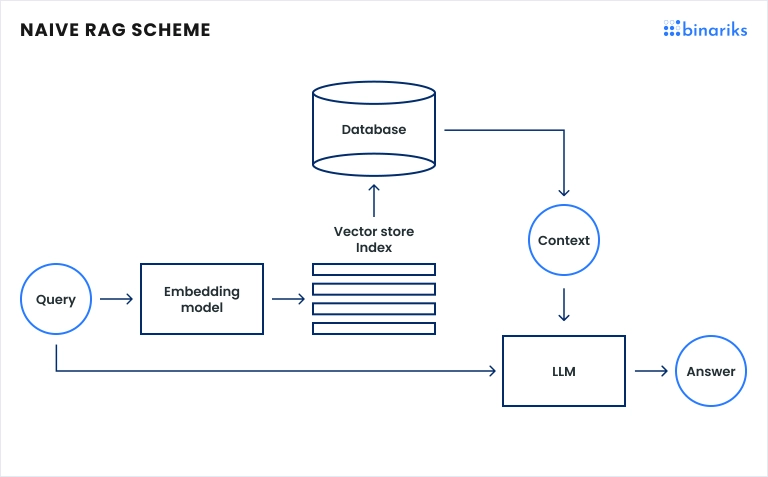
In general, its main idea arises from the following structure:
- Documents are parsed into text
- Text from the documents is pre-processed and split into chunks
- Chunks are further processed by encoder-based LLM that generates text embeddings
- Text embeddings are stored into the vector database
When the user asks some specific questions:
- The user's question is pre-processed and converted into text embedding by the same LLM used for document processing
- Search over vector database is performed to extract the most similar text embeddings to the question embedding
- Those Most similar text embeddings are mapped into text chunks
- Text chunks are fed into decoder-based text generation LLM as a context with a prompt and user question, so LLM now has added knowledge (from the document-specific text chunks) on the topic and can formulate answers using this information
This allows for reducing the probability of LLM hallucinations and increasing the probability of LLM generating answers based on the company-specific documents. There are different modifications of this approach that may involve results reordering, multiple LLM queries, etc., but the main idea does not change.
So, it seems like the solution vision is ready. However, the tricky part is that there is no predefined document structure, so there may be plain-text PDFs with arbitrary headings and documents consisting of tables or images.
While it is still possible to parse data using some well-known OCR libraries or PDF parsers, loss of real word and phrase structure is almost inevitable, and this could significantly affect chatbot performance.
That is the point where the complexity of a document understanding arises. Before that, we thought of just "reading text" and our understanding of required "intelligence" was limited with some OCR at max. Yet now, we also need to understand layout structure to determine tables and their parts, define headings and subheadings, etc.
Moreover, suppose images are also widely spread throughout documents and not supplemented with sufficiently clear captions. In that case, it is possible that we need to incorporate sophisticated image-to-text solutions—multimodal AI that can perceive visual content in the form of text.
Here is how one task is converted into three to fulfill business requirements:
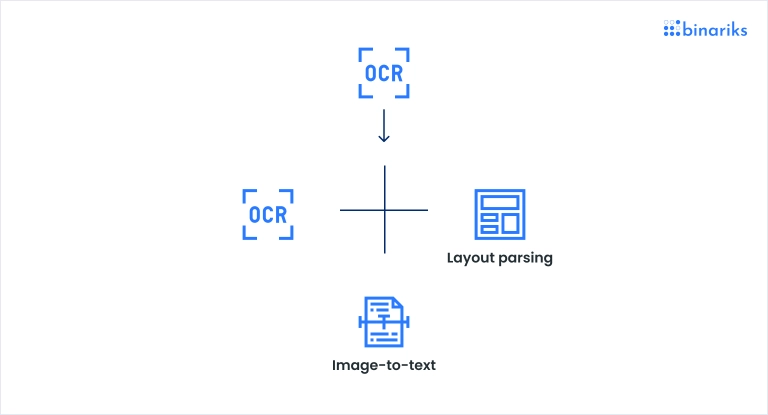
This simple sample application illustrates how an obvious, at first glance, solution requires a myriad of intelligent components to cover the business case. We suggest that this is a good starting point for the next chapter.
Why is it hard to achieve 100% fully automated IDP results?
From the example above, you may already feel that IDP success heavily depends on the data structure and clear final business goal. And it does, but there are some underlying reasons that supplement and explain the origins of the complexities already mentioned, and understanding these reasons helps foresee and prevent them in the early stages.
One more note before digging into the origins—we mention all these not to say that IDP is impossible but to highlight that careful business analysis supplemented with data science and machine learning expertise is essential to building a successful IDP system, and we at Binariks know how to help you excel in the confusing world of IDP.
To summarize, depending on the business goal, IDP unfolds through a series of stages, beginning with the extraction of data from documents, followed by its analysis.
This process is nuanced and heavily dependent on whether the input document is structured—think JSON, CSV, XML, HTML, text documents with some stable structure — or unstructured, like images or scans of complex documents with tables, figures, multiple fields that may arise in different positions throughout the document, etc. The methodology for data extraction shifts accordingly, as do possible pitfalls.
Crafting specific adaptors is essential for documents in a structured format. These adaptors are tailored to decode information based on the document’s structure and convert it into some programming abstraction to be moved to structured data storage like table rows in the database.
An example of an adapter mechanism that can convert structured documents into a form that can be further processed with traditional programming is regular expressions.
Regular expression is a rule-based text parsing technique widely used in Natural Language Processing (NLP) to extract specific fields from structured texts. These can include content between specific XML tags, FHIR messages, or fields with a well-defined and stable format from plain-text documents, like emails, mobile phones, etc.
Regular expressions and other rule-based engines, a staple of the old days, performed admirably under the conditions of structural stability. Yet, their efficiency wanes with any alteration in the document’s structure, rendering the results unpredictable or even null. Moreover, these algorithms describe logic predefined by its nature, so it is impossible to learn and adapt from new data automatically.
In contrast, unstructured information such as images and scans continues to be the domain of more intelligent solutions. These include OCR, document layout parsing, image-to-text conversion, and their orchestration with LLMs. These LLMs replace the traditional explicit programming logic for data manipulation with the ability of machine learning models to learn and reason based on the data's hidden features and relationships.
These unstructured IDP techniques are also similar to a specialized adaptor, adept at transforming image data into text and, depending on the tools used, enhance it with additional info on the structure, meaning, etc. Its role in converting vast quantities of physical documents into digital format cannot be understated, marking a significant leap forward in document digitization.
However, as mentioned, their efficacy is bounded by several constraints. Let's briefly review some of them and outline the main reasons:
1. Language, font, domain compatibility
Like humans, ML models are trained on data to model this data, and, like humans, they make mistakes on data they don't know or know badly.
Thus, if you use an OCR tool trained in English only using some typical fonts, it will not be able to understand other language words. Moreover, it will likely make mistakes on some particular fonts—not recognizing characters.
The same applies to the LLMs: models trained to recognize/generate texts of some specific domain and language may not be efficient on the others.
2. Bad quality of source images
While the bad quality of source images can be mitigated using specific image pre-processing techniques—it is still essential to check the quality of your data.
Even the best methods cannot fix completely broken data, as the quality of the images is crucial for gathering quality information from them.
3. Absence of contextual information
Like in the example from the previous section, sometimes you could build a reasoning machine on the raw text only, but in most cases, you need to gather lots of supplementary information, as structure plays a significant role in the correct text interpretation.
4. Absence of answer or field
Even if you have lots of good data to train models and great pre-processing on the inference, the information you seek may be elsewhere. The important thing here is to be honest with your customer and not to allow LLM to make up an answer and cheat.
And talking about data, if you need to find a sustainable way to store and process it, here at Binariks, we have extensive Big Data competence . We can help you gain insights from the data using AI and organize robust data pipelines. Our expertise in Big Data allows us to create efficient solutions that ensure your data is properly managed and utilized.
5. Errors in testing
It is a common step to build tests for ML models that check the model's accuracy on the test data. The same applies to the IDP, and you will likely build test sets to validate the aspects or whole of your IDP pipeline. It is very common to make mistakes during this step, and many things can go wrong—you could use the wrong metrics or even build the wrong test set or testing strategy.
It is crucial to be very careful when testing ML models and to combine synthetic testing with testing on real-world users. Sometimes, it may even appear that the test you have created is not like the real users' use of your IDP.
To sum up, data is crucial . Even if you understand the internals of your business goals and select the right tools that fulfill your business needs and data type, you need to make sure that the data you have covers your cases.
Intelligent solutions provide added value by covering complex fuzzy cases. They can make mistakes, but they can also learn. Thus, careful model design and training are crucial.
Unlock your data's potential: discover Binariks' Big Data and analytics services today!
What options and tools should be considered?
The evolution of AI has created new opportunities in document processing. Major cloud providers such as AWS, GCP, and Azure introduced offerings that simplify the configuration burden and provide a one-stop shop for all workloads.
Here, we will examine different options that might be considered during IDP implementation and provide suggestions for tools that can be used to complete some specific tasks.
Cloud providers offer various AI services and promise to provide the required tools to build an IDP solution in minutes without any programming experience, like Vertex AI from GCP. While these services are good options for validating some ideas, they may be limited in terms of configuration and ability to extend with custom logic.
In this section, we will review some possible use cases to reveal the broader landscape of AI tools that may be applied depending on your business needs.
Let's assume there is a need to build a tool that automates the time-consuming task of document categorization to eliminate manual work, save costs, and reduce human errors.
Enthusiastic marketing specialists and salespeople promoting various IDP services are everywhere these days. They present their solutions as the only required tools that can solve your task and offer even more. Additionally, experienced machine learning engineers are full of ideas on how to tackle this task using sophisticated machine learning models.
However, a proper way is to start with a detailed business analysis, understanding the needs and AI applicability, and only after that can you be sure which tools are the right ones. The core is to define an idea of criteria; the documents are to be categorized.
This brings us to the variety of toolsets based on the needs. For example:
Document categorization for contracts and claims
If you are working with some kind of claims or contracts, it is common to categorize documents based on some specific field values, for example personal identification numbers (PIN), signatories or some other fields that distinguish documents. This brings us to the idea of entity recognition and further categorization of documents, based on the common entities.
Depending on the entities you want to detect, you may consider using cloud solutions, for example Amazon Comprehend or Azure AI Language services, which offer a built-in functionality to detect multiple entities on the documents, like personal identification numbers. These services also allow you to train custom models on your data, to extract some specific fields that they originally are not able to detect.
Yet, this comes with the additional cost and binds you to the platform. To overcome this limitation you may want to consider using open-source solutions. This opens another door of opportunities and more technical options to be considered.
Typically, named entity recognition (NER) is a task performed on text, not document scans or images. Thus, we need to perform OCR first, using libraries like PyTesseract, PaddleOCR, or others to extract text, and then train a custom NER model, for example, utilizing the spaCy NLP library.
While this is a viable solution, you may run into the already mentioned problem of complex layouts, when to get meaningful text you first need to extract its layout. This brings us more tools, such as AWS Textract, a cloud-based tool that can extract document layout and its content (text) from PDF documents with great precision.
But what if you could use one model that takes a PDF scan or image and extracts the named entity from it in one go? Open-source models LayoutLM and Donut are capable of doing this, and when using them, you avoid the additional steps of OCR, layout parsing, and NER on the extracted text.
Handling fuzzy data in document processing
If your data is fuzzy and there are no common entities to extract group documents based on them, we need to dig into document content understanding.
Depending on your business case, this may include document classification if, after business analysis, you know the "buckets" for documents or you require some document clustering or topic modeling—a term more often used in document processing, to define the "buckets."
While many traditionally used machine learning methods may be applied, nowadays, this is a realm of using LLMs.
This does not mean that you entirely throw away all the classical ML methods; for example, one of the best techniques for topic modeling nowadays—BERTopic, heavily relies on many sophisticated ML methods, like HDBSCAN, UMAP, and others. Still, it also utilizes LLMs to achieve great text-embedding vectors.
The same stands for document classification. While utilizing zero-shot classification with LLMs is widespread, you often still need to address traditional ML classification models, like XGBoost or RandomForest.
Take your software to new heights with tailored AI/ML solutions
Which LLM to choose?
So, which LLMs to use? For the POC or MVP solutions, we recommend starting with one of the multiple LLM APIs:
- OpenAI API or Azure OpenAI if you require higher stability and have privacy constraints
- Google AI with Gemini model
- Claude API
- Cohere API
- Amazon Bedrock (while Amazon does not provide "its own" LLM, they host multiple open-source LLMs, for example, LLAMA-3)
These services are suitable not only because they offer the largest versions of LLMs without the need to pay for expensive hosting and developing LLM code infrastructure but also because they provide multiple versions of models, both for text and text-embeddings generation and other tasks.
Also, most libraries, like LongChain and LlamaIndex, designed to ease LLM application development, have good integration with the APIs from the cloud providers and Open AI, as they were the pioneers in this field.
Here are some notes on training custom LLM on your data. This may sound like a perfect idea to fulfill business needs and blow up marketing with announcements of the development of a generative AI by your business—"custom LLM from…".
Still, we must warn that training a model whose performance is compatible with GPT-4 is extremely costly. The main reason lies in the amount of computational resources required to process that many parameters. For example, LLAMA-3-70B has 70 billion parameters, and GPT-4 is even larger.
At the same time, there are smaller but very performant LLM options like Mistral 7B, Meta-Llama-3-8B, and their variants with much lower amounts of parameters that could be pretty easily fine-tuned using techniques like QLoRA. However, expediency, requirements, and details of LLM finetuning are other (equally fascinating) topics for next time.
Yet, suppose you want to fine-tune an open-source model (Donut, LayoutLM, others) for document layout understanding, entity recognition, or any other task. In that case, you will likely consider renting a virtual machine with a GPU from some major cloud providers.
While this is a viable solution, starting with something free or cheap is always better. An excellent option for training initial models is Google Colaboratory, which provides lots of free resources (GPU as well, but CPU is not as powerful) and is a great place to train prototype models.
In case more resources are required, the good options to check are services provided by large cloud providers, as they also allow you to create inference pipelines after the models are ready: Azure Notebooks, AWS SageMaker, and Google Vertex AI. It is always a good idea to check cloud providers for startup support programs that may grant free credits for compute resources.
After selecting the open-source model from Hugginface or training your own model, you must integrate it into your code. In this case, much depends on the model size and computational requirements.
Serving ML models of different kinds and sizes can be tricky, but let's consider a model that requires GPU during inference and is not used constantly. Thus, we do not need a constantly running VM with GPU on a cloud.
The good choice here is to check serverless GPU providers. The concept of serverless GPU is highly related to the concept of serverless computing in general. As analog with, for example, AWS Lambda, which utilizes resources only when being called, serverless GPUs work similarly—you do not need to pay for idling GPUs, only for the time they are used.
Another benefit is the ease of scalability. There are serverless GPU offerings from large cloud providers, like AWS SagaMaker Serverless Inference, but it may be difficult to figure them out.
Smaller providers like Runpod IO, Replicate, and Mystic AI are also worth mentioning. They often offer an easier start and lower pricing, charging for the time you use their services. This variety of GPUs makes them a flexible and cost-effective choice for many.
Replicate and Mystic AI already have most popular ML models deployed and provide them through APIs. Runpod is also offered as a platform for model training.
Of course, if you are considering developing and hosting your ML model, you should also examine other providers or ask Binariks for professional assistance .
Conclusion
This exploration into the world of Intelligent Document Processing has provided insights and foundational knowledge, yet it represents only the initial steps into a broader and more complex field. While we have dived into various aspects of IDP, many applications, such as visual question answering, research, and technical nuances, have only been mentioned.
The future of IDP is destined for even more incredible advancements, particularly with the rise of multimodal AI models. These models, like Donut, LayoutLM, the new GPT-4o, and others, combine text, visuals, and other mediums to understand documents better. This multimodality promises to revolutionize the IDP field, enabling more accurate and context-aware document processing.
As we continue to innovate, the potential of these advanced capabilities makes us excited and optimistic about the evolution of IDP and the more efficient document processing solutions it will bring.
Author

Share