
The shift from data warehouse to lakehouse in data architecture came gradually with the evolution of data itself. Data warehouses gained mainstream adoption in the 1980s and 1990s to support column-structured systems for large-scale analysis, a technology that was new at the time. They replaced RDBMS systems because they could focus on large datasets.
In the 2000s, the industry went through another shift with the rise of unstructured big data, forced by the development of the internet. Hadoop is an open-source framework that emerged then to store and process large volumes of unstructured and semi-structured data across distributed clusters of commodity hardware. However, it was complex, slow, and had limited schema flexibility. Coupling storage and computing was also a problem. It was time for a more flexible and user-friendly architecture .
This led to the rise of data lakes in the 2010s, which were more flexible and affordable. It worked well with structural data, decoupled storage, and compute for independent scaling. Data lakes offered the flexibility and affordability enterprises needed to keep up with modern data volume and variety.
However, they, too, had shortcomings: poor governance, lack of schema enforcement, and inconsistent performance for analytics. As a result, many data lakes became disorganized and difficult to use.
Over the past decade, data architecture has evolved as businesses began collecting unstructured inputs like logs, sensors, and social media. Traditional data warehouse solutions and newer data lakes started to show their limits.
To bridge the gap between the structure of warehouses and the flexibility of lakes, the data lakehouse emerged in the late 2010s and early 2020s. It introduced a unified architecture that combines the low-cost, scalable storage of a data lake with the transactional integrity, schema management, and performance of a data warehouse. Built on open table formats like Delta Lake, lakehouses support ACID transactions, schema enforcement, and governance on top of low-cost object storage.
The shift from data warehouse to data lakehouse reflects a growing need for unified, scalable platforms that support everything from real-time business intelligence (BI) to advanced machine learning.
Keep reading to learn how to migrate to a lakehouse.
From data warehouses to data lakes: A quick recap
Let's briefly revisit two existing traditional approaches to storing and managing large volumes of data:
Data warehouse
A data warehouse is a centralized, structured repository for fast querying and reporting. It stores data in a predefined schema and is optimized for analytics, particularly business intelligence use cases. The data that is stored in a warehouse is clean and processed. Data warehouses store only cleaned data.
- Advantages: Reliable performance, consistency, and strong support for structured data and SQL-based tools.
- Limitations: High cost, rigid schema requirements, and less suitable for unstructured or semi-structured data. It also has issues with processing streaming data and is generally hostile to introducing new types of data.
Data lake
A data lake is a more flexible storage system that allows raw, unstructured, semi-structured, and structured data to coexist in their native formats by applying a schema on read data instead of stored data. Basically, it stores all types of raw data.
- Advantages: Scalability, low-cost storage, and support for various data types.
- Limitations: Lack of schema-on-write can lead to data quality issues, making querying and governance more complex. A data lake lacks support for SQL without additional tools. Quality and governance of data may be inconsistent, resulting in disorganized data. There are also issues with data security.
While data warehouse and data lake technologies each brought unique strengths, neither alone could meet the demands of AI in data quality and diverse data formats.
What is a data lakehouse?
A data lakehouse is a modern data architecture that blends the best features of data warehouses and data lakes. It combines the scalability and flexibility of lakes with the performance, reliability, and structure of warehouses by layering ACID transactions, schema enforcement, and fast query engines over low-cost object storage.
This hybrid approach solves the shortcomings of both systems: it avoids the high cost and rigidity of warehouses while also preventing the data sprawl and quality issues often found in lakes.
A data engineering lakehouse is better than a warehouse because it can store raw data. It is also better than a data lake because it can consistently support reliable data management.
Data lakehouse benefits:
- It handles structured, semi-structured, and unstructured data.
- It stores raw data affordably using scalable object storage.
- It allows you to work with different vendors and tools for data storage without being tied to just one.
- It ensures reliable updates with ACID transaction support.
- It supports both BI and machine learning from a single platform.
- It applies schemas with clear validation rules to support data quality.
- It is scalable separately for storage and computing.
- It allows for real-time analytics of streaming data.
- It supports AI adoption through appropriate security, the ability to combine diverse data with metadata, and support for computing resources that enable AI accelerators.
- Data lakehouse has centralized data storage, which reduces data redundancy by avoiding data duplication.
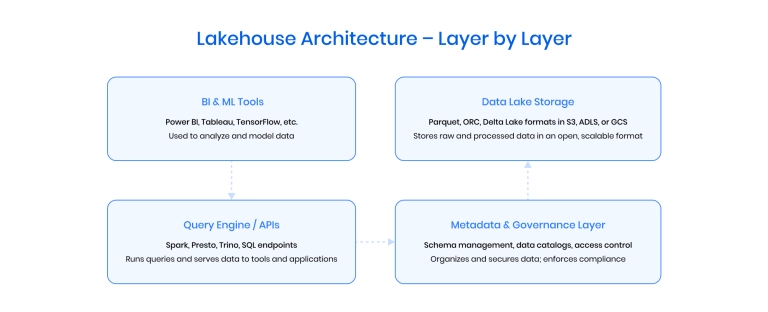
Key differences between warehouse, lake, and lakehouse
While data warehouses, data lakes, and data lakehouses are all used to store and analyze data, they differ significantly in their capabilities.
Data warehouse is built for structured data and fast SQL-based analytics. It's ideal for business intelligence but offers limited flexibility with unstructured data and is expensive to scale.
Data lake is designed to store large volumes of raw, semi-structured, and unstructured data at a low cost. However, it lacks built-in data management and governance, often leading to disorganized "data swamps."
Data lakehouse is a hybrid approach that combines the scalable storage and flexibility of a data lake with the structure, performance, and governance features of a data warehouse. In this way, it is more well-suited for BI and machine learning workloads.
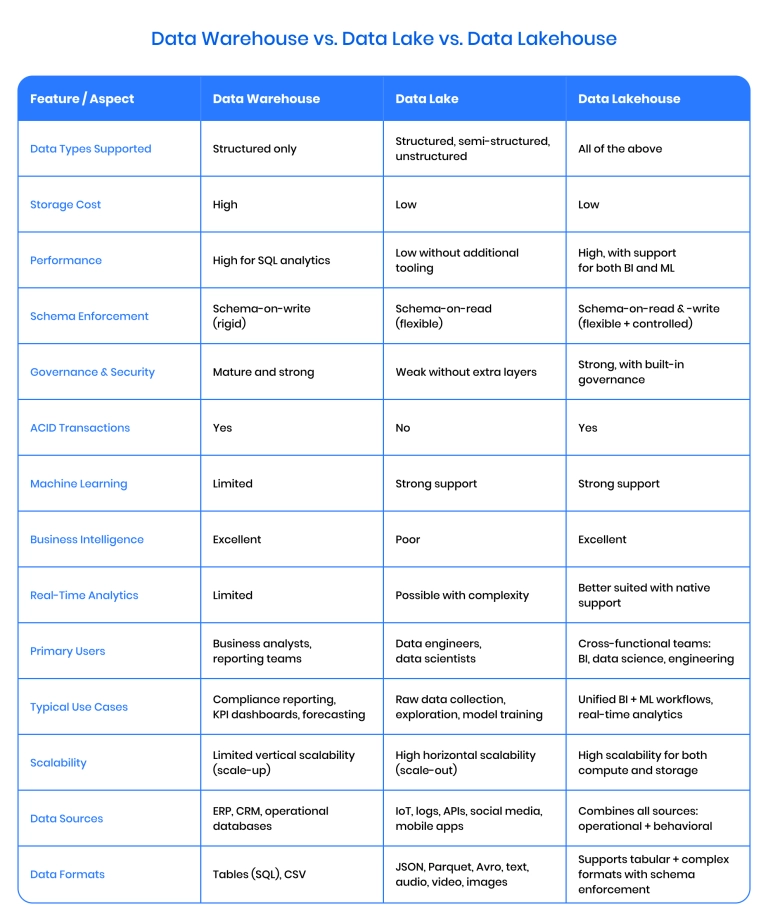
The choice of data warehouse vs. data lakehouse vs. data lake ultimately depends on factors related to data: the type of data you use, the source of data, and the ways you plan to use the data. Here is a brief consensus on how data warehouse vs. data lake vs. data lakehouse should be utilized:
- Use a data warehouse for fast, reliable reporting on structured data.
- Use a data lake if you need scalable storage for all types of raw data.
- Use a data lakehouse to get the best of both worlds – advanced lakehouse analytics, flexible storage, and strong governance.
Why businesses are migrating to lakehouse
There are plenty of reasons for businesses to move from data warehouse to data lakehouse. Data is becoming increasingly complex, and there is a need for more advanced data analytics. At the same time, businesses are exploring ways to reduce infrastructure costs by extending their enterprise data warehouse with lakehouse capabilities.
- Big data processing
Lakehouses are built to handle massive volumes of structured and unstructured data efficiently. This makes them ideal for collecting, storing, and analyzing high-volume digital data sources, such as logs, IoT feeds, user activity (clickstreams), and app telemetry, at scale and without requiring heavy preprocessing. This is great for streaming platforms, e-commerce apps, and industrial IoT operators.
- Real-time analytics
Unlike traditional warehouses, lakehouses can support near real-time data ingestion and querying. This enables faster decision-making, especially in dynamic business environments.
- Machine learning-ready
Lakehouses provide a unified data architecture platform that allows raw and processed data to coexist. This allows data scientists to train ML models directly on the data without moving it across systems.
- Lower infrastructure costs
Lakehouses leverage cost-effective cloud data object storage (like S3, GCS, or ADLS) while still offering the performance of a data warehouse. This means significant savings on storage and computing.
- Simplified architecture
Instead of maintaining both a lake and a warehouse, businesses can streamline operations with a single platform that supports BI, ML, and ELT pipelines.
- Better data governance
Modern lakehouse solutions have metadata tracking, fine-grained access control, and data lineage features. This helps to manage data more effectively.
Lakehouse use cases across industries
The lakehouse architecture is especially impactful in industries where data complexity, volume, and regulatory demands are high. Here are some real-world examples:
Healthcare: Accelerating research and clinical decision support
Healthcare organizations must unify EHR data with clinical notes, imaging, and genomics – all while maintaining HIPAA compliance. Lakehouses are especially powerful for research hospitals that combine structured health records with radiology scans and handwritten notes to build diagnostic models and support real-time clinical decision systems.
- Stores diverse data types (DICOM, HL7, doctor notes) securely
- Supports predictive analytics like readmission risk and patient deterioration alerts
- Enables ML workflows and self-service exploration for clinical teams
Real example:
Regeneron adopted a Databricks lakehouse to analyze over 100 PB of genomic and clinical data, reducing drug discovery timelines from months to days.
Finance: Real-time risk analysis and personalized banking
Fintech companies rely on real-time data to detect fraud and improve personalization.
- Combines streaming data (e.g., Kafka) with historical transaction records
- Powers machine learning for fraud detection and AI-enabled credit scoring
- Simplifies SOX and PCI DSS compliance with built-in governance
Real example:
Robinhood uses a lakehouse on Databricks to centralize fraud detection and customer engagement analytics.
Insurance: Smarter claims and fraud detection
Insurance companies often deal with both structured policy data and unstructured adjuster notes, claim photos, and third-party documents.
- Merges claim histories with field evidence for automated assessment
- Detects fraud through ML-based anomaly detection
- Tracks data lineage for regulatory reporting
Real example:
Swiss Re, a global reinsurer, uses a lakehouse architecture to streamline claims processing and integrate structured and unstructured data for underwriting and risk assessment.
Sales: Predicting churn and unlocking upsell opportunities
Sales organizations need unified access to CRM records, customer support logs, and product usage data.
- Combines structured CRM data with semi-structured behavioral signals
- Enables churn prediction and revenue forecasting via ML
- Provides real-time sales dashboards
Real example:
HubSpot uses a lakehouse model with Snowflake to blend sales, support, and product data – powering lifecycle scoring and pipeline visibility across teams.
IoT: Fault detection and equipment optimization
Manufacturers and industrial firms collect continuous data streams from machines, sensors, and vehicles.
- Stores time-series data alongside maintenance logs and operator notes
- Supports real-time alerting and predictive maintenance
- Enables equipment failure prediction using AI models
Real example:
GE Digital leverages a lakehouse approach with Delta Lake to manage IoT sensor data from industrial equipment to reduce downtime through predictive analytics.
Pharmaceuticals: Faster, smarter drug development
Pharma companies must integrate clinical trial data, lab research, and manufacturing quality logs to meet regulatory and development timelines.
- Harmonizes preclinical, clinical, and supply chain datasets
- Speeds up modeling for efficacy and safety predictions
- Simplifies FDA submission prep with version-controlled data
Real example:
AstraZeneca built a lakehouse-powered analytics platform to combine real-world evidence with trial data and accelerate insights across its R&D pipeline.
Telecom: Real-time network optimization
Telecom providers collect terabytes of daily data from towers, users, and mobile apps.
- Ingests real-time network data for outage detection and optimization
- Powers churn models and targeted service offers
- Ensures data privacy compliance (GDPR, CCPA) through fine-grained access
Real example:
T-Mobile implemented a Databricks lakehouse to unify customer, billing, and network analytics; this improved user targeting and reduced dropped calls.
Government & public sector: Secure, collaborative data access
Agencies need secure, controlled access to sensitive data across departments (e.g., courts, law enforcement, healthcare).
- Centralizes structured and unstructured records for shared access
- Enables case analytics, resource forecasting, and fraud detection
- Provides audit trails to meet NIST, FedRAMP, and GDPR standards
Real example:
The UK Ministry of Justice uses a lakehouse to integrate court records and operational data for better resource allocation across the legal system.
Challenges of transitioning to data lakehouse
While the benefits of the data lakehouse architecture are clear, transitioning to (especially from traditional warehouses or fragmented data lakes) is not without challenges. These hurdles in lakehouse implementation can be both technical and organizational, and addressing them early is key to a successful migration.
Here are the key challenges that emerge when transforming from data warehouses to data lakehouses:
Legacy systems and technical debt
Many organizations still rely on outdated legacy data warehouses or on-premise systems. Migrating from these tightly coupled architectures to a cloud-native lakehouse often requires:
- Refactoring existing pipelines
- Rebuilding integrations
- Modernizing outdated schemas and file formats
Data governance complexity
Lakehouses offer flexibility, but that comes with the risk of losing control over data access, quality, and lineage. Key issues include:
- Defining ownership in a decentralized environment
- Enforcing consistent data cataloging and metadata standards
- Implementing fine-grained access control across tools and teams
Security and Compliance Risks
Sensitive data (e.g., personal health information or financial details) requires robust protection. Migrating to a lakehouse demands:
- End-to-end encryption and access control
- Audit trails and monitoring for compliance (HIPAA, GDPR, SOC 2)
- Zero-trust architectures across hybrid and multi-cloud setups
Upskilling data teams
Lakehouse environments combine data engineering, analytics, and ML. Teams must adapt to new tools like:
- Delta Lake / Apache Iceberg / Hudi
- Spark, PySpark, or SQL-on-lake engines
- Modern orchestration tools (e.g., Airflow, dbt)
This often requires retraining data professionals and revisiting workflows.
Cost management and resource planning
Though lakehouses are cost-efficient long-term, initial migration and scaling costs can spike due to:
- Dual-running legacy and lakehouse platforms
- Increased storage and computing for data duplication
- Misconfigured clusters or resource overprovisioning in early phases
Organizational resistance to change
Change management is a major hurdle. Leadership may hesitate due to unclear ROI, while teams resist adopting new workflows. Common blockers:
- Siloed departments with conflicting priorities
- Lack of executive alignment or data strategy
- Poor documentation of current processes
Tooling and integration gaps
Existing BI, ETL, and data quality tools may not support lakehouse-native formats or frameworks out of the box. Teams face:
- Compatibility issues with legacy dashboards
- Gaps in ML/AI pipelines if tools are hard-wired to old systems
- Vendor lock-in risks when choosing cloud-specific solutions
Your data should drive growth, not confusion. Let's fix that!
How Binariks helps businesses implement modern data architectures
At Binariks, we help organizations move confidently from outdated or fragmented data systems to data lakehouses. We support the entire process of warehouse-to-lakehouse migration from start to finish and implement scalable, governed lakehouse data platform solutions tailored to modern business needs.
Here is a brief look at our capabilities to give you an idea:
- Cloud-native data platforms
We build scalable data architectures on AWS, Azure, and Google Cloud to support modern analytics and storage needs.
- Data warehouse & data lake consulting
We offer strategic consulting to assess your current data architecture and plan its evolution. Our data warehouse consulting helps optimize performance and align data models with business needs, while our data lake consulting focuses on unstructured data. We guide you in choosing the right tools and designing a clear roadmap before implementation begins.
- Data lakehouse implementation
We design and deploy lakehouse environments using Delta Lake, Apache Iceberg, or Hudi, which are fully integrated with BI and warehouse tools.
- End-to-end data pipelines
We create robust batch and streaming pipelines using Apache Spark, Kafka, Airflow, and dbt for efficient data movement and transformation.
- Data governance & security
Our solutions ensure data control and compliance through encryption, access management, and lineage tracking, aligning with HIPAA, GDPR, and SOC 2.
- Advanced analytics & ML
We empower teams to run analytics and ML directly in the lakehouse using Python, SQL, and open-source frameworks without data duplication.
Binariks can help you:
- Migrate from legacy systems without disruption
- Design a future-proof architecture tailored to your use case
- Empower your teams with flexible, secure, and governed access to data
- Enable ML and BI from a unified data platform
The shift from data warehouse and data lakehouse platforms reflects a broader industry move toward unified analytics environments. Lakehouse architecture offers the best of both worlds – the scalability and flexibility of a data lake with the structure and performance of a warehouse. With data growing rapidly and AI advancing, now is the time to transition to a lakehouse.
Contact Binariks for a consultation or to initiate your data architecture modernization project.
Author

Share