
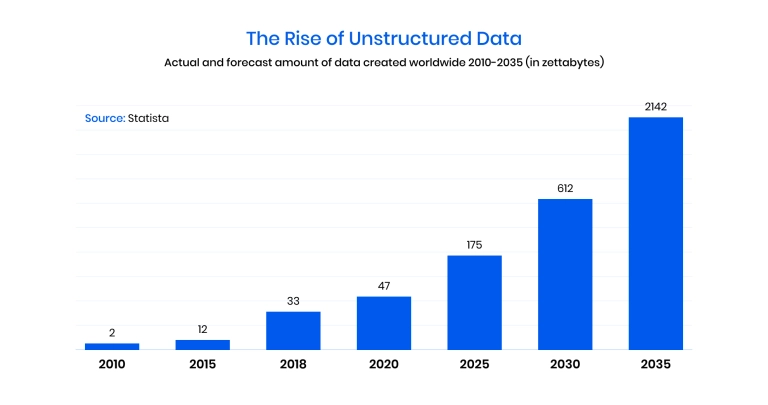
The data created over the next 3 years is expected to exceed what was created over the past 30 years. Businesses are drowning in raw, unstructured content, and most of it remains untouched. Traditional search can't scale. LLMs hallucinate without context. What's needed is a bridge from scattered data to clear, reliable answers, and that's where RAG pipelines come in.
Retrieval-Augmented Generation (RAG) combines the reasoning power of large language models with trusted, real-time retrieval, giving you accuracy, traceability, and real business impact. According to IDC, the world will generate over 175 zettabytes of data by 2025, but only about 10% will be stored, and even less analyzed. Most of it will be unstructured. That's not just inefficiency; it's a missed opportunity.
In this article, you'll learn:
- How businesses move from scattered documents to actionable intelligence
- What makes RAG different and better than other approaches
- The architecture behind a scalable RAG pipeline
- Real-world use cases across industries
- A step-by-step RAG implementation workflow
- Key metrics to track success
- A case study of how Binariks made it work for an enterprise client
Ready to unlock value from your data? Let's get into it.
From data swamp to insights
Over 80% of enterprise data is unstructured – stored across emails, scanned contracts, support tickets, cloud drives, and legacy archives. This data is often invisible to analytics tools, disconnected from decision-making processes, and vulnerable to breaches.
According to IBM, the sheer volume and diversity of unstructured data make it difficult to manage, secure, and scale. And with IDC projecting a 21.2% annual growth rate over the next five years, the problem is only getting worse.
Here's why unstructured data is a serious operational risk:
- Low visibility: Scattered across cloud, on-prem, and third-party systems, making it hard to find or classify.
- Manual overload: Traditional tools can't keep up with volume or complexity.
- Siloed apps: Hundreds of cloud tools generate isolated data with poor integration.
- No ownership: Orphaned files and unclear accountability increase compliance risk.
These challenges directly impact productivity, increase storage costs, and open the door to security threats. That's where RAG pipeline architecture offers a practical path forward. Instead of training a model on everything, RAG retrieves only the relevant context in real time, turning unsearchable archives into accurate, contextual responses.
At Binariks, we help companies build a RAG pipeline tailored to their domain, compliance needs, and infrastructure. Through our Generative AI development services, we deliver scalable solutions that unlock the value trapped in unstructured data.
What is RAG and why does it change the game
Retrieval-Augmented Generation (RAG) combines LLMs with real-time search, retrieving relevant context from external data to generate accurate, grounded responses — unlike models that rely only on pre-trained knowledge.
The core components of the RAG framework include:
- Retriever – identifies and fetches relevant documents or passages from a vector database or an indexed source.
- Generator – an LLM that uses the retrieved context to produce informed, natural-language responses.
- Knowledge store – the structured or unstructured data sources (files, PDFs, knowledge bases) indexed for retrieval.
RAG stands out by combining reasoning and retrieval. Unlike RPA or ETL, which only move data, or LLMs that may hallucinate, RAG delivers accurate, context-aware answers grounded in real sources.
Let's make some comparisons to dig deeper.
| Approach | Core Capability | Strengths | Weaknesses | Use Case Fit |
| RAG pipelines | Real-time generation with retrieval | Context-aware, traceable, grounded responses | Requires well-prepared data sources | Search, Q&A, customer support, decision-making |
| LLMs (only) | Pre-trained generation | Fast, creative, general-purpose output | Hallucinations, outdated info | Content creation, code suggestions |
| RPA/ETL | Rule-based extraction and transfer | Reliable for structured data workflows | No reasoning, no unstructured input | Data migration, reports, integration |
| Search engines | Keyword-based document retrieval | Fast and simple | No synthesis, low precision | Lookup tasks, navigation |
Core architecture of a RAG pipeline
The foundation of any successful RAG system implementation is a modular architecture that connects raw data to a language model through intelligent retrieval. This structure allows teams to keep responses accurate, current, and grounded in internal knowledge, without retraining the model on every update.

Key components of a classic RAG system:
- User query: A user submits a question, which is converted into a vector that captures its meaning.
- Vector database: Stored document chunks are embedded and indexed for fast similarity search.
- Context retrieval: The system finds and returns the most relevant pieces of content.
- LLM generation: The model uses this context to generate accurate, grounded responses.
- Response: The answer is returned via chat, API, or internal tool – fluent, traceable, and context-aware.
Understanding this architecture is essential for anyone looking into how to build a RAG pipeline that performs reliably across domains and scales with changing data, without compromising speed or quality.
High‑impact use cases
From automating insurance claims to improving clinical accuracy and simplifying banking operations, building RAG pipelines allows enterprises to extract value from their unstructured data faster, more accurately, and with greater confidence.
Below are three practical, real-world examples of RAG implementation that highlight what’s possible across key verticals.
Insurance
In the insurance sector, claims processing often involves navigating siloed, unstructured content – policy PDFs, voice notes, CRM records, and scanned forms.
MongoDB demonstrated how insurers use Atlas Vector Search and LLMs to build RAG-powered claim adjuster tools. The system lets adjusters ask plain-English questions, retrieves relevant documentation via vector search, and feeds it into the LLM for grounded answers.
The results:
- Claims resolved faster with less manual effort;
- Data retrieved from multiple legacy sources without custom APIs;
- Architecture extended to customer service and underwriting use cases.
Healthcare
A 2024 arXiv study tested a RAG system implementation for preoperative guidance, built on 35 official medical guidelines. The system used LangChain, LlamaIndex, and Pinecone to retrieve the most relevant medical guidance for each user query, which was then passed to GPT-4 for response generation.
Key outcomes:
- RAG-enhanced GPT-4 achieved 91.4% accuracy, higher than junior doctors (86.3%);
- Response times were reduced from 10 minutes to under 20 seconds;
- The system demonstrated scalability and non-inferior performance compared to human clinicians.
Banking
A 2025 research project introduced CAPRAG , a hybrid RAG solution designed for digital banking. It combines vector retrieval with graph-based search (Neo4j) to answer customer questions and generate structured financial reports. CAPRAG demonstrates how RAG pipeline architecture can unify free text and relationship data within a single AI-powered interaction layer.
Highlights:
- Dual retrieval: vector (semantic) + graph (relational);
- Supports both user-facing chat and internal reporting tools;
- LLM synthesizes results from both sources in real time.
Binariks' case
In one of the most demanding enterprise RAG implementation case studies, Binariks partnered with a global commercial insurer (50,000+ employees, $45B+ annual revenue) to transform legacy, document-heavy workflows into a scalable, explainable, AI-driven system.
The client faced mounting regulatory pressure, slow claims processing, and heavy manual overhead in reviewing thousands of complex documents tied to legal, risk, and policy analysis. They needed a solution that would be secure, audit-friendly, and fast, without compromising accuracy.
Our approach combined multiple core elements:
- OCR pipelines for digitizing scanned legal and insurance documents;
- RAG architecture built on LangChain, LangGraph, and OpenAI APIs – with traceable, citation-backed answers;
- Prompt engineering using Chain-of-Thought (CoT) strategies and Reflection Agents for self-evaluated, multi-step reasoning;
- Evaluation layer via LangSmith to monitor precision, trace failures, and optimize prompts in production;
- Enterprise-grade deployment on Azure with full encryption, Key Vault integration, and CI/CD pipelines.
This project followed strict security protocols: no external LLM hosting, only whitelisted Azure services, and encrypted data at rest and in transit. All components were containerized, test-covered, and structured for scale.
Key results:
- 90% faster extraction and analysis of risk data;
- 80-90% reduction in manual review cycles;
- 20-30% better LLM output quality using Reflection Agents;
- Real-time claim triage and reduced SLA violations;
- Significant reduction in reliance on senior analysts;
- The foundation was laid for a 5x scale via microservice-based architecture.
This initiative showcases the best practices for RAG implementation in complex, high-risk environments, from deep integration with enterprise infrastructure to real-time performance optimization.
For more details, please, check out this case study on AI claims analysis .
RAG implementation workflow (step‑by‑step)
Implementing a production-grade RAG pipeline requires a structured approach that moves from raw data to deployed systems, with validation, iteration, and monitoring built in. Below are the five key stages for enterprise-ready RAG.
1. Data audit & PII mapping
Before building, identify and clean your data.
- Map unstructured sources (docs, logs, wikis);
- Tag sensitive info (PII, PHI);
- Standardize formats, remove duplicates;
- Align access with InfoSec and compliance.
2. Proof of concept with accuracy targets
A PoC tests if the RAG algorithm improves outcomes.
- Choose one use case (e.g., claims, audit search);
- Load sample data and run queries;
- Compare vanilla LLM vs. RAG results;
- Measure accuracy, hallucinations, and latency.
3. Full ingestion & vector indexing
This phase builds the retrieval layer – the core of RAG development.
- Chunk and embed text using a domain-fit model;
- Store vectors in Pinecone, Weaviate, etc.
- Add metadata for smart filtering and ranking.
4. Evaluation: precision & factuality
Validate that the system is reliable in real-world use.
- Score top-K document relevance;
- Check factual accuracy of generated answers;
- Test edge cases and hallucination resistance;
- Ensure the RAG pipeline stays grounded and traceable.
5. Deployment & continuous feedback
Going live means continuous monitoring and iteration.
- Integrate with apps, chatbots, or tools;
- Track usage and feedback to refine performance;
- Re-index and retrain as content evolves;
- Apply MLOps to support scaling and stability.
A good RAG pipeline isn't static, it's continuously monitored and optimized through real usage and feedback loops.
RAG challenges and how to mitigate them
While powerful, RAG systems come with challenges that can stall or derail implementation if not addressed early. Below are common issues and how to solve them.
- Low retrieval precision
Irrelevant results lead to weak answers. Fix it with better chunking, stronger embeddings, and metadata filters. A clean vector store is how RAG pipelines improve LLM accuracy.
- Hallucinations despite retrieval
Even with context, LLMs can invent facts. Use context-only prompting, limit token overflow, and apply citation tracing for reliability.
- Latency and scaling issues
Large indexes or high query volume can slow response times. Optimize top-K retrieval, use GPU inference, and cache frequent queries.
- Lack of evaluation frameworks
Without metrics, you can't measure value. Use labeled queries and precision benchmarks, which have been proven in real examples of RAG implementation.
- Misalignment with business goals
RAG won't stick if it doesn't solve real problems. Tie every system to a clear outcome. If you're still asking what RAG pipelines are for, the use case isn't defined tightly enough.
These are technical problems, but solving them well is a business advantage. And that's where implementation expertise matters most.
Success metrics that matter
A successful RAG implementation isn't just about functional output, it must drive measurable impact. Below are core metrics to check out.
| Metric | What It Measures | Why It Matters |
| Accuracy | % of responses grounded in retrieved content | Shows how well the system answers with facts, not guesses |
| Retrieval precision | % of relevant documents among top-K results | Determines the quality of the vector index and retriever |
| Hallucination rate | % of outputs containing unverifiable or incorrect info | Lower rate = more reliable, auditable answers |
| Time-to-answer | Avg. seconds to return a complete response | Critical for user satisfaction and internal efficiency |
| Content coverage | % of topics or queries the system can respond to accurately | Indicates domain robustness and training completeness |
| Agent productivity | % reduction in manual search or task time | Connects RAG to actual team efficiency gains |
| Audit traceability | % of responses that include source references | Key for regulated industries where explainability is required |
| Regulatory readiness | % of outputs that pass compliance checks (e.g., GDPR, HIPAA) | Ensures legal defensibility of AI-generated responses |
The right metrics depend on your use case, but if you're not tracking both technical precision and business impact, you’re missing half the picture.
Why choose Binariks for custom RAG pipelines
Binariks delivers full-cycle RAG solutions, from initial scoping to secure, production-grade deployment. Our cross-functional teams combine deep expertise in LLMs, vector databases, prompt engineering, and enterprise infrastructure to ensure every pipeline is accurate, explainable, and scalable.
What we provide:
- End-to-end RAG architecture tailored to your domain and data
- Compliance-first design for regulated industries
- Integration with enterprise platforms like Azure, AWS, and GCP
- Advanced techniques: CoT prompting, Reflection Agents
- Proven success in high-stakes sectors like insurance and healthcare
With a focus on measurable results, fast iteration, and long-term value, Binariks helps enterprises turn their data into trusted, real-time intelligence.
Final thoughts
RAG pipelines are now driving real impact across industries. From faster decision-making to audit-ready AI outputs, the value is clear. But to get it right, you need more than just the right tools; you need experience, precision, and a focus on outcomes.
Binariks helps you go beyond prototypes and build RAG systems that scale with your business. Contact us , and let’s turn your unstructured data into intelligence that works.
Author

Share