
Traditional data exchange models rely on centralized processing, which requires transmitting large amounts of data to a central server. This approach increases the risk of data breaches, as sensitive information is constantly being transferred and stored in one location. It also creates network congestion and higher latency, especially when real-time decision-making is needed. As the volume of data grows, these systems become more challenging to scale, making them less efficient for modern AI applications.
Federated learning is a feasible solution to the issues in traditional data exchange. It is a decentralized, privacy-preserving approach crucial in healthcare, finance, and other regulated industries where data confidentiality is essential. By keeping data local and sharing only model updates, federated learning efficiently enables secure AI training while ensuring compliance with data-sharing regulations like HIPAA and GDPR.
In this article, we explore distributed learning and federated learning in particular. We focus on the mechanism of action, potential issues, and use cases of federated learning (FL).
Understanding distributed systems
Federated learning is distributed learning that focuses on data privacy-preserving AI, where model training happens across decentralized devices without sharing raw data. To understand it, it is important to look into distributed systems first.
Distributed systems are a collection of interconnected computers or devices that work together as a single system to perform tasks. They communicate over a network and can operate independently while sharing resources.
Key characteristics:
- Decentralization – No single point of control; nodes operate autonomously.
- Scalability – The system can expand easily by adding more nodes.
- Fault tolerance – If one node fails, the system continues functioning.
- Parallel processing – Tasks are executed simultaneously on multiple devices, improving efficiency.
Advantages of loosely coupled systems for data exchange:
Loosely coupled systems are distributed systems where components have minimal dependencies on each other, making them highly flexible and resilient to changes. Here is the list of benefits of federated learning:
- They are flexible, meaning the nodes can be added or removed without affecting the entire system.
- They support horizontal scaling with minimal disruptions.
- Loosely coupled systems have high fault tolerance: if one node fails, others continue operating, so there is no point of failure.
- Parallel request processing speeds up operations.
- There is a reduced load on individual nodes.
- Loosely based systems use APIs, asynchronous communication, or event-driven architecture (EDA) for efficient data exchange.
- Independent components can communicate using different protocols and data formats.
- There is a reduced impact of changes – updating or modifying one node does not require changes across the entire system.
- Microservices architecture is well-suited for loosely coupled systems. It makes sense to contrast Monolith VS. Microservices here.
- Monolithic architectures are rigid and harder to scale, while microservices enable flexibility by allowing independent components to interact via APIs. This makes FL more scalable and resilient, as AI models can evolve independently without system-wide disruption.
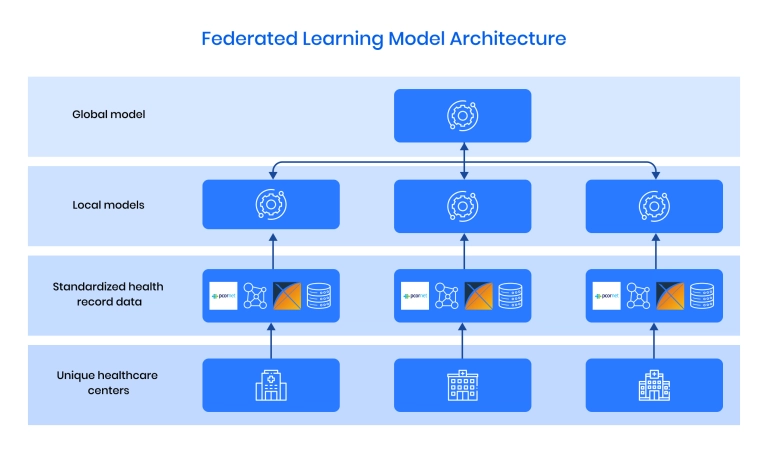
So, what is federated learning exactly? It is a machine-learning approach where multiple decentralized devices (nodes) train a model collaboratively without sharing raw data with global servers. It enables privacy-preserving training by keeping data localized while only transmitting model updates. The data remains on the local server, a significant benefit for privacy and security.
Core principles of federated learning (FL)
- Decentralized training – Data remains on user devices, while only model updates are aggregated centrally.
- Privacy-preserving AI – Ensures data security by keeping personal or sensitive information local.
- Communication efficiency – Reduces the need for extensive data transfers by sharing only model parameters.
- Personalization & adaptability – Allows models to be fine-tuned based on user-specific data without exposing private information.
- Scalability – Supports big data analytics and enables AI training across thousands or millions of edge devices, such as smartphones, IoT sensors, or medical institutions.
Here are the actual ways in which federated learning models ensure privacy:
- Secure aggregation ensures that model updates from different clients are combined using cryptographic methods. This prevents individual data exposure.
- Differential privacy adds noise to updates to ensure that specific data points cannot be reconstructed.
- Encryption and secure multiparty computation (SMPC) encrypt model parameters before transmission to protect against interception.
- Local processing ensures all training occurs on devices, so raw data is never sent to external servers.
- Federated averaging (FedAvg) refines the global model by averaging updates from multiple devices, which prevents any single device from having too much influence.
- Federated Stochastic Gradient Descent (FedSGD) allows clients to compute gradients locally based on their data, sending only gradient updates to the central server for aggregation. This ensures privacy while enabling collaborative model refinement, with larger datasets contributing more significantly to updates.
One of the key mechanisms in the federal learning setup is orchestration. AI orchestration manages and coordinates decentralized devices to ensure proper model training. It involves various processes that optimize the system:
- A subset of devices is selected for training in each round while ensuring they meet computational and network requirements.
- The global model is sent to selected clients, and their locally trained updates are aggregated to refine the model.
- Communication between clients and central servers is managed according to existing network overload.
- Privacy-preserving techniques such as differential privacy and homomorphic encryption are enforced to ensure data security.
- Techniques like personalization layers are implemented to handle non-identically distributed (non-IID) data and adapt the global model to individual users' needs.
AI that works for your business – scalable, secure, and high-performing solutions tailored to your goals
Tech issues in distributed systems and federated learning
Both distributed systems and federated learning (FL) share several technical challenges due to their decentralized nature and reliance on multiple independent nodes. While FL offers privacy-preserving AI, it introduces complexities in communication, data heterogeneity, security, and resource management that must be carefully addressed. Here are the most common issues related to federal learning and their solutions:
1. Communication overhead & latency
Problem:
- In distributed systems, continuous synchronization between nodes increases network traffic, leading to latency and performance bottlenecks.
- Frequent model updates from multiple clients in federated learning systems create high bandwidth usage, especially when dealing with large models or frequent updates. Maintaining synchronization among thousands of devices, each updating at its own pace, further adds complexity.
Solution:
- Compression techniques: FL uses quantization and sparsification to reduce the size of model updates. Distributed systems leverage data compression and edge computing to minimize network load.
- Asynchronous processing: Both systems benefit from asynchronous updates to reduce waiting times and balance load. FL can allow clients to send updates at different times instead of waiting for all participants.
- Efficient data aggregation:
- Federated Averaging (FedAvg) reduces the number of updates sent in FL.
- Batching requests and using content delivery networks (CDNs) help optimize performance in distributed computing.
2. Data heterogeneity & imbalance
Problem:
- Non-IID Data: Data across different devices or nodes can vary significantly in quality, quantity, and distribution. For example, smartphone users have unique usage patterns, and medical devices may record demographic-specific data. This heterogeneity complicates model convergence and performance consistency.
- Imbalanced data: Some devices generate large datasets while others contribute very little, biasing the global model toward data-rich participants.
Solution:
- Adaptive learning strategies: Local models can be fine-tuned using meta-learning or transfer learning to improve performance on diverse datasets.
- Clustered training approaches: Grouping similar devices based on data patterns helps improve personalization and model consistency.
- Weighted model aggregation: Adjusting model contributions based on the quality and size of local datasets prevents overfitting to dominant devices.
3. Resource constraints & model complexity
Problem:
- FL participants (e.g., smartphones and IoT devices) often have limited processing power and memory. This has a negative impact on training efficiency.
- Aggregating model updates from thousands or millions of devices increases algorithmic complexity.
Solution:
- Adaptive workload distribution: Assigning lighter tasks to less powerful devices prevents system overload.
- Edge computing integration: Moving computations closer to devices reduces reliance on centralized cloud processing.
- Model optimization techniques: Using pruned, quantized, or lightweight models minimizes computational requirements.
4. Security & privacy risks
Problem:
- Poisoning attacks: Malicious actors may send corrupted model updates to degrade performance.
- Model inversion attacks: Attackers can attempt to reconstruct sensitive training data from shared model updates.
- Lack of direct supervision: Since raw data remains on user devices, detecting fraud or manipulation is more difficult.
Solution:
- Robust anomaly detection: Monitoring updates for suspicious patterns helps identify poisoned contributions.
- Secure aggregation: Encrypting updates using homomorphic encryption or secure multiparty computation (SMPC) protects data integrity.
- Differential privacy (DP): Adding controlled noise to updates makes it harder for adversaries to extract private data.
5. Scalability issues & model management
Problem:
- Managing and aggregating models across millions of devices requires sophisticated algorithms to prevent bottlenecks.
- Ensuring global model quality and consistency becomes increasingly complex as the number of participants grows.
Solution:
- Hierarchical aggregation: FL can implement federated hierarchical learning, where intermediate nodes collect updates before sending them to the global server.
- Edge-based coordination: Processing updates at edge nodes before full aggregation reduces the strain on central servers.
- Blockchain for trust management: Distributed ledgers can provide tamper-proof validation of model contributions.
Applications across industries
Healthcare & smart hospitals
- Hospitals use FL to train disease detection models across multiple institutions without sharing raw patient data, improving accuracy in diagnosing conditions like cancer and heart disease.
- Wearables and smart devices use FL to securely collect and analyze health data from multiple users without sharing their personal information. This allows them to track trends and detect issues in real time to prevent chronic conditions like diabetes.
- FL allows hospitals and research institutions to collaborate on rare disease research without exposing patient records.
- Medical imaging models benefit from FL by training on diverse datasets.
Transportation & autonomous vehicles
- Self-driving cars use FL to learn from real-world driving data without exposing sensitive driver information.
- Vehicle sensors process traffic and environmental conditions at the edge, reducing latency in collision detection and lane prediction models.
- Smart cities integrate FL to optimize traffic flow, public transportation schedules, and parking availability, improving urban mobility while keeping vehicle data local.
Smartphones, wearables & mobile applications
- Mobile devices use FL to improve predictive text (e.g., Gboard), face recognition, and voice assistants (e.g., Siri, Google Assistant) without compromising privacy.
- Smartwatches and fitness trackers analyze activity levels, heart rate, and sleep patterns locally.
- FL enhances personalized app recommendations, allowing platforms like TikTok, YouTube, and Spotify to refine content suggestions without collecting user data centrally.
Finance & fraud detection
- Banks improve fraud detection models by training on decentralized transaction data while ensuring that customer financial records remain private.
- FL enhances credit scoring models by learning from multiple financial institutions, helping assess creditworthiness without aggregating personal data.
- Personalized banking services benefit from FL by tailoring financial recommendations based on user behavior.
Retail & e-commerce
- FL improves product recommendation engines in platforms like Amazon and Netflix by learning from individual user interactions without collecting personal data.
- Retailers optimize inventory management and supply chain logistics by training models on sales trends across multiple locations while keeping transactional data confidential.
- E-commerce businesses detect payment fraud and fake reviews by analyzing customer activity at the edge.
Industrial IoT, manufacturing & predictive maintenance
- Factories use FL to predict machine failures before they occur, reducing maintenance costs and improving operational efficiency.
- Industrial robots and AR/VR-assisted assembly lines train object detection models locally.
- Smart sensors analyze real-time temperature, humidity, and energy consumption to optimize environmental monitoring and workplace safety.
Smart cities & environmental monitoring
- FL enables smart city applications like traffic optimization, waste management, and energy efficiency improvements while keeping IoT sensor data secure.
- Environmental agencies use FL to analyze air pollution levels and climate trends, improving sustainability efforts without sharing sensitive geographic data.
- Emergency services train AI models using FL to predict natural disasters, manage evacuations, and improve response times.
Education & adaptive learning systems
- Adaptive learning platforms use FL to personalize lesson plans, quiz difficulty, and course recommendations based on student progress, all while preserving privacy.
- Universities and research institutions collaborate using FL to analyze student performance data without centralizing sensitive academic records.
Role of edge computing in enhancing federated systems
Edge computing is a technology that processes data closer to its source, such as on smartphones or IoT devices, instead of relying on centralized cloud servers.
It enables local model training in federal learning, reducing latency and bandwidth by keeping data on the device instead of sending it to a central server. Devices compute model updates locally instead of transmitting raw data and only share model parameters with a central server or aggregator for decentralized AI training.
While not a necessity for every federated learning setup, edge computing is used when low latency, privacy, and efficient data processing are critical. It is most beneficial in scenarios where:
- Real-time AI decisions are needed – applications like autonomous vehicles, industrial automation, and smart grids require instant AI inference, which edge computing enables.
- Network bandwidth is limited. In remote areas, edge computing reduces data transmission requirements for IoT networks or mobile devices with unstable internet connectivity.
- Privacy and security are priorities – Healthcare, finance, and personal AI assistants (e.g., Google Assistant, Siri) rely on edge computing to keep sensitive data on the device.
- Device heterogeneity needs optimization – Edge computing helps low-power devices participate in FL by offloading heavy computations to nearby edge servers.
Final thoughts
To conclude, privacy-centered collaborative AI of the future in regulated industries is impossible without federated learning systems. As data volumes grow and compliance requirements tighten, organizations need secure, scalable, and efficient AI solutions to handle big data analytics while maintaining privacy.
Binariks can help a partner company implement federated learning by:
- Building custom FL architectures tailored to industry needs.
- Integrating FL with edge computing and cloud platforms for efficiency.
- Enhancing security with encryption, differential privacy, and secure aggregation.
- Optimizing FL models for IoT , mobile, and enterprise systems.
- Providing end-to-end FL solutions, from setup to performance monitoring.
Author

Share