
Modern businesses no longer just run on software; they run on data. When that data is delayed or corrupted, the negative impact is immediate and very expensive. This new reality requires a new discipline to support the quality, availability, and stability of data infrastructure – data reliability engineering.
In this article, we cover the essentials of data reliability engineering: overall role, responsibilities, and tools. We also explain how it differs from SRE and how it is explicitly used in connection with AI.
What is data reliability engineering?
Data reliability engineering (DRE) is a discipline that oversees the performance of data systems and infrastructure. Data reliability engineering focuses on ensuring data quality, maintaining data integrity, and providing secure access to data.
This is achieved through monitoring, alerting, and automation to detect and fix issues in data pipelines (e.g., delays, data corruption, job failures). A data reliability engineer builds resilient and reliable data pipelines and collaborates with other teams, including Data Engineers, Analysts, and Site Reliability Engineers, to ensure the operational stability of the data infrastructure.
The key principles of DRE are:
- Quality: Involves data validation, anomaly detection, and cleansing.
- Availability: Focuses on minimizing downtime and enabling fast recovery.
- Stability: Designs systems to withstand failures and data source changes.
In short, data reliability engineering is similar to site reliability engineering but focused on data.
Why data reliability matters in a data-driven world
Poor data quality costs organizations an average of .9 million annually, according to Gartner's 2020 research. Data reliability engineering (DRE) is more important now than it was a few years ago because the stakes for trustworthy data in production have dramatically increased.
Here is why: first, data products are always on, as they power real-time AI/ML models and embedded analytics. Moreover, data pipelines have become more complex, and organizations now treat data like software. All of these make data reliability more crucial. Without reliability, even the most well-defined data strategy falls apart.
Here are a few illustrations of the true cost of data reliability in AI systems. Back in 2018, there was a well-known case of Amazon scrapping its internal AI recruiting tool after discovering it discriminated against women due to biased training data. Cases like that cost companies millions of dollars in immediate financial damages and even more in long-term reputational damages.
In an even more dramatic example, 16,000 COVID-19 cases were omitted from the daily reports in the UK due to an IT error in 2020 during the midst of the pandemic. This was due to a minor mistake, exceeding Excel's row limit (65,536 rows in XLS format).
The result of this error was a significant delay in contact tracing efforts across the UK. The risk of uncontrolled virus spread skyrocketed because the missing 16,000 positive cases were not reported on time.
The UK government faced harsh public and media criticism, and the incident highlighted the dangers of relying on outdated tools, such as Excel, for managing critical public health data.
Cases like these illustrate that data reliability best practices are not to be compromised. AI/ML models trained on faulty data carry their risks as they deliver biased or potentially harmful outcomes.
Key responsibilities of data reliability engineers
- Monitor data pipelines: Continuously check pipeline health to detect failures early.
- Set up alerts: Configure automated notifications for critical issues, such as data anomalies.
- Test and validate data: Apply checks, such as schema validation or null value limits, to ensure data accuracy.
- Establish feedback loops and audits: Regularly review quality metrics, gather feedback from data consumers, and refine systems over time.
- Test pipelines during development: Catch issues early by validating logic, inputs, and edge cases before deployment.
- Implement observability: Add tracking to make data behavior visible across systems.
- Manage data SLAs: Define and monitor expectations for timely and reliable data delivery.
- Proactively identify risk areas: Use lineage and historical patterns to spot weak points in the data ecosystem before they fail.
- Remediate and recover from data failures: Fix broken datasets, reprocess missed loads, and restore downstream trust after pipeline or logic errors.
- Track and measure system reliability: Collect metrics that reflect overall stability, including failure rate and recovery time.
- Empower data scientists with quality metrics: Support data scientists by validating inputs and ensuring models use trusted data. Share clear quality scores and usage rules.
- Enforce data contracts: Ensure that upstream and downstream systems agree on the structure and meaning of data. This helps prevent silent schema changes from breaking pipelines.
- Collaborate across teams: Collaborate with engineers and analysts to ensure that systems are both reliable and user-friendly.
Core tools and technologies in DRE
1. Monte Carlo
How it works:
Monte Carlo connects to your data warehouse and automatically monitors for issues like missing data or schema changes. It alerts you when something breaks without needing manual setup.
Best for:
Teams that want automated data quality monitoring with minimal configuration.
2. Databand (by IBM)
How it works:
Databand integrates with orchestration tools to monitor pipeline health. It helps detect delays or failures early by tracking job execution and data flow.
Best for:
Teams that need operational visibility into how pipelines run.
3. Great Expectations
How it works:
You write rules (called expectations) that check your data for things like nulls or value ranges. These checks run during processing and generate reports on data quality.
Best for:
Teams that want customizable, test-driven validation for their data. Especially those building a data strategy for small businesses and seeking to identify issues early without requiring heavy infrastructure.
4. dbt Tests
How it works:
Within your DBT project, you define simple tests like “not null” or “unique.” These run automatically and help ensure clean, reliable data models.
Best for:
Teams using dbt for SQL transformations who want lightweight built-in testing.
5. Airflow
How it works:
Airflow uses Python scripts to define and schedule workflows. It manages dependencies and retries tasks that fail.
Best for:
Data engineers run scheduled pipelines and ETL processes.
6. Dagster
How it works:
Dagster lets you build pipelines from modular Python components. It emphasizes structure, data observability, and testing to make workflows easier to maintain and manage.
Best for:
Teams seeking a modern alternative to Airflow with enhanced developer tools.
7. OpenLineage
How it works:
OpenLineage collects metadata about data movement and builds a visual map of how data flows across systems.
Best for:
When teams need to understand how changes in one part of the system affect others.
Struggling with data bottlenecks? Let's break them together!
7 best practices for ensuring data reliability
1. Build in data quality checks early
Use tools like Great Expectations or dbt tests to validate data at the ingestion and transformation stages. Check for:
- Null values
- Duplicates
- Schema mismatches
- Unexpected distributions
Tip: Automate these checks in your CI/CD workflows.
2. Implement end-to-end observability
Instrument pipelines with tools like Monte Carlo, Databand, or OpenLineage to track:
- Failed runs
- Data delays
- Volume anomalies (e.g., unexpected row counts or sudden drops)
Tip: Surface data issues early through automated alerts and monitoring.
3. Define ownership and quality standards
Set clear expectations across teams for data reliability.
- Define responsibilities
- Create data contracts
- Document usage standards
Tip: Use shared documentation and version control to align teams.
4. Design for failure
Expect that the infrastructure will break at some point. Build systems and processes to minimize impact.
- Use staging environments
- Prepare rollback plans
- Conduct failure simulations
Tip: Make incident reviews a regular part of your data operations.
5. Orchestrate with recovery in mind
Use orchestration tools like Airflow or Dagster to:
- Create retry logic
- Track dependencies
- Handle partial failures
Tip: Prioritize fast detection, clean alerts, and smooth recovery paths.
6. Automate repetitive tasks
Reduce manual work by scripting common operational steps.
- Data validations
- Deployment
- Monitoring
Tip: Use reusable code modules for consistency.
7. Test before production
Control data releases and prevent downstream breakage by testing changes before deployment.
- Load test in staging
- Involve stakeholders early
- Validate against production-like data
Tip: Always have a rollback plan in place.
DRE vs. Data Engineering vs. SRE
DEs, DREs, and SREs each play a crucial role in the modern data stack. However, they serve different purposes:
- DEs build the pipelines,
- SREs ensure infrastructure stays up,
- DREs make sure the data flowing through those systems is dependable.
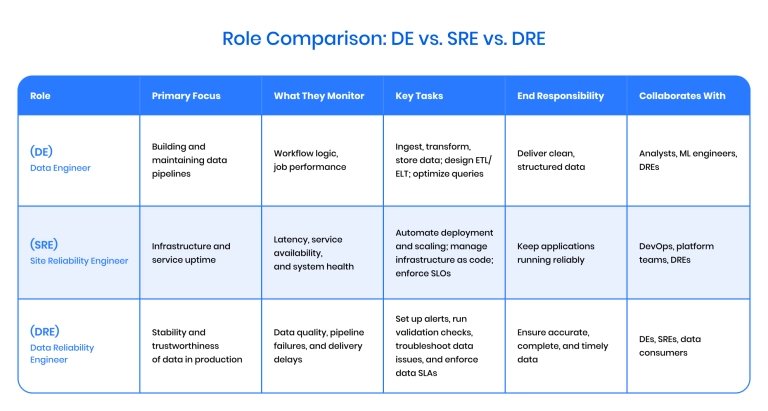
Data Engineer (DE)
Focus: Builds and maintains data pipelines and infrastructure.
Key responsibilities:
- Ingest, clean, and transform data
- Design and manage ETL/ELT workflows
- Optimize data storage and query performance
- Deliver structured data to analytics and ML teams
Goal: Provide usable, high-quality data to downstream systems and users.
Connection to other roles:
- Works with analysts, ML engineers, and DREs
- May report to a Data Platform Lead or Head of Data
- Builds pipelines that DREs monitor in production
Site Reliability Engineer (SRE)
Focus: Ensures the reliability and performance of the production software infrastructure.
Key responsibilities:
- Monitor system uptime and latency
- Manage infrastructure as code
- Automate deployments and recovery
- Enforce SLAs/SLOs for services
Goal: Maintain software services with minimal downtime and ensure reliable operation.
Connection to other roles:
- Works with DevOps, platform teams, and DREs
- Reports to an SRE Manager or Infrastructure Lead
- Supports the systems' data tools that rely on
Data Reliability Engineer (DRE)
Focus: Ensures reliability of data in production environments.
Key responsibilities:
- Monitor and troubleshoot data pipelines
- Enforce data SLAs and implement quality checks
- Detect and resolve issues like delays or schema changes
- Track data lineage and assess the downstream impact
- Collaborate with DEs and SREs on observability and recovery
Goal: Ensure that data remains correct, complete, and available.
Although closely related to DE and SRE roles, the DRE fills a specific gap by focusing on reliable data delivery in production. The role often evolves from either discipline but requires dedicated attention to data consistency.
Connection to other roles:
- Bridges DE and SRE teams
- Reports to a Data Platform or Engineering Manager
- Supports data consumers by maintaining dependable pipelines
Data reliability engineering in the age of AI
Data reliability engineering with AI is even more demanding than traditional data reliability engineering. AI systems are only as good as the data that feeds them, and when that data is flawed, whole models you spend years developing don't work properly.
Here is what makes DRE more mission-critical for the combination of AI and data reliability engineering:
- AI needs ongoing clean data, not just one-time inputs.
- Pipeline issues disrupt real-time inference and model outputs.
- Many failures start upstream, beyond the scope of model monitoring.
- Insufficient data amplifies bias and risks in AI applications.
How AI is enhancing data reliability engineering
It's not just that data reliability engineering is more mission-critical in the age of AI. AI for data reliability is an enhancer with all of the tools available on the market. Here is how:
Anomaly detection at scale
AI-powered platforms like Monte Carlo and Databand detect issues such as:
- Schema changes
- Volume spikes or drops
- Unexpected nulls
- Late or failed deliveries
This reduces reliance on manual rules and enables early warnings across critical pipelines.
Intelligent root cause analysis
Modern tools use AI to trace the origin of failures by analyzing incident lineage.
- Monte Carlo's Incident IQ highlights impacted tables and dependencies.
- OpenLineage can help prioritize issues based on downstream impact.
This approach shortens time-to-resolution and prevents repeat incidents.
Automated data testing and suggestions
AI can suggest validation rules by learning from past incidents and profiling patterns, e.g.:
- Value range checks
- Uniqueness constraints
- Row count thresholds
Tools like Great Expectations, when enhanced with profiling, make testing smarter and less manual.
Forecasting data SLAs and risk
Predictive models assess the likelihood of SLA breaches based on usage history and system patterns.
This is especially beneficial in environments with seasonal traffic spikes or interdependent systems. It enables teams to take action before users are impacted.
AI assistants for debugging and insights
Some teams integrate AI copilots into Slack or dashboards to:
- Explain pipeline failures
- Recommend fixes based on similar past incidents
- Surface relevant logs and lineage traces instantly
These assistants act like real-time, context-aware teammates during incident response.
Final thoughts
In today's data-driven economy, unreliable data isn't just a technical issue but a direct threat to decision-making, customer trust, and AI performance. Data Reliability Engineering (DRE) has become essential for businesses that depend on real-time analytics, complex pipelines and AI systems.
At Binariks, we help organizations embed reliability into their data infrastructure from the ground up. We can:
- Design and implement a DRE strategy tailored to your business needs, industry, and tech stack
- Build and optimize resilient data pipelines using tools like Airflow and Dagster
- Set up end-to-end observability with Monte Carlo, Databand, OpenLineage, or custom solutions
- Automate data quality validation through smart testing frameworks and anomaly detection
- Implement real-time monitoring and alerting to detect failures before they reach users
- Define and enforce data SLAs and contracts to align teams and ensure accountability
- Integrate AI for root cause analysis and risk prediction across your data systems
- Support cross-functional collaboration between data engineers, SREs, analysts, and business teams
- Refactor outdated workflows
- Offer data engineering services to support ETL development and pipeline reliability
- Provide data warehouse consulting for designing or modernizing your storage infrastructure
If your business runs on data, it deserves to run on dependable data.
Let's make your pipelines not just operational – but trusted, observable, and future-proof.
FAQ
Author

Share