
The business world is inundated with data. Every interaction, transaction, and click yields valuable information, and the ability to effectively utilize this data is crucial for the success of every modern company. Data engineering bridges raw data and actionable insights, designing, building, and maintaining the systems that collect, store, and analyze this information.
At Binariks , we recognize the ever-growing importance of data engineering. Our team has helped businesses unlock the power of their data by creating robust, secure, and adaptable solutions for about ten years. We constantly monitor the big landscape and every data engineering trend, ensuring our tools and projects evolve alongside the latest advancements.
This article will describe the top 10 data engineering trends shaping how we manage data in 2026 and beyond. Through this exploration, you'll gain a clear understanding of:
- The latest technologies that are changing how data engineering is done;
- The impact these technologies will have on our ability to process, store, and analyze data;
- How these advancements can empower businesses to leverage their data for a significant competitive edge.
Unveiling the present landscape of data engineering
The sphere of data engineering is currently experiencing explosive growth. This surge is a direct consequence of the ever-increasing volume of generated data. Here is the visual representation of the situation according to Statista:
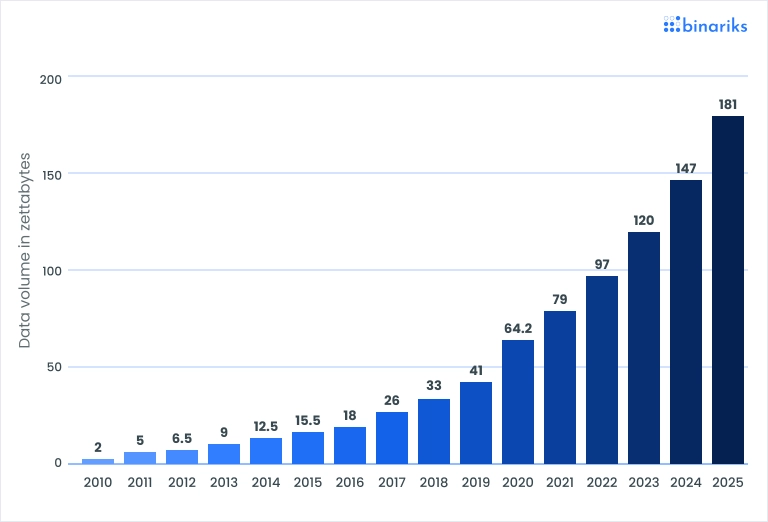
And according to Cisco, the annual internet traffic has already crossed the benchmark of one zettabyte, which is millions of gigabytes, or 1000000000000 GB of data.
Companies require robust systems for collecting, storing, processing, and analyzing this data. Data engineers address this challenge by using a diverse arsenal of technologies and practices.
- Data warehouses: These act as centralized repositories for historical data, typically structured for efficient analysis. Data warehouses allow businesses to gain insights into trends, customer behavior, and market performance.
- Data lakes: Unlike structured data warehouses, data lakes provide a more flexible storage solution. They can hold all of a company's data, regardless of format – structured, semi-structured, or unstructured. This allows for broader and potentially more insightful data exploration.
- ETL pipelines: The ETL (Extract, Transform, Load) process remains a fundamental concept in data engineering. It involves extracting data from various sources, transforming it into a usable format for analysis, and loading it into a data warehouse or data lake. ETL pipelines ensure data consistency and quality before feeding it into analytical tools.
- Streaming data technologies: Real-time data processing is becoming increasingly important. Streaming data technologies enable businesses to analyze data as it's generated, allowing for faster decision-making and near-instantaneous responses to events.
- Cloud infrastructure: Cloud computing has revolutionized data engineering by offering a scalable and cost-effective platform for data storage and processing. Cloud platforms allow data engineers to easily scale their infrastructure up or down based on changing data volumes. A KDnuggets survey underscores the growing significance of cloud computing platforms like AWS, Azure, and GCP, alongside the rising demand for real-time data processing frameworks like Apache Kafka and Spark Streaming (Source ).
- Data integration tools: Data rarely exists in isolation. Data engineers rely on integration tools to connect to diverse data sources, seamlessly move data between them, and ensure a unified data landscape for analysis.
But what should companies pay attention to in the near future to avoid falling behind and keep up with data engineering innovations? Check out the next section.
10 future trends in data engineering
As the field of data engineering technologies constantly evolves, businesses need to be aware of emerging trends. Here, we explore the top 10 trends significantly impacting data engineering practices from 2026 to 2028.
1. Real-time data processing
To stay competitive, organizations need to make data-driven decisions quickly. Real-time data processing technologies enable companies to analyze data as it's generated, allowing for near-instantaneous responses to events, improved customer experiences, and real-time operations optimization.
The real-time analytics market is projected to grow from approximately USD 14.5 billion in 2023 to over USD 35 billion by 2032, driven by the proliferation of event-driven architectures and streaming platforms such as Apache Kafka, Apache Flink, and cloud-native equivalents like AWS Kinesis and Google Pub/Sub.
In 2026, the architectural conversation has matured beyond "Should we stream?" to "How do we unify streaming and batch?"
The lakehouse paradigm, combining the flexibility of data lakes with the query performance of warehouses, is enabling organizations to run real-time ingestion alongside historical analytics in a single system. Platforms such as Apache Iceberg and Delta Lake have become de facto standards for this unified approach.
A key engineering challenge is maintaining exactly-once semantics and low-latency SLAs at scale. Organizations are increasingly investing in stream processing expertise, and 72% of IT leaders incorporate streaming for mission-critical operations.
2. Cloud-native data engineering
Cloud platforms offer many advantages for data engineering, including scalability, cost-effectiveness, and ease of use. By migrating to cloud-based solutions, data engineers can leverage pre-built services, elastic resources, and automated infrastructure management, freeing them to focus on core data engineering tasks.
According to Gartner, over 95% of new digital workloads will be deployed on cloud-native platforms by 2028, up from 30% in 2021.
AWS, Google Cloud, and Microsoft Azure have matured their managed data services so much that most infrastructure setup can now be done by declaring what you need, and the platform handles the rest.
The practical shift centers on FinOps discipline and cost governance. As cloud bills have grown alongside data volumes, engineering teams are under pressure to implement intelligent tiering, spot instance orchestration, and auto-scaling policies that balance performance with spend.
Multi-cloud and hybrid strategies have also matured. Enterprises with regulatory or latency requirements are no longer forced to choose a single provider; data mesh architectures and open table formats enable portability across cloud environments without vendor lock-in.
3. Integration of AI and machine learning
AI-augmented data engineering means automated pipeline generation, intelligent anomaly detection, self-healing infrastructure, and LLM-powered data transformation. The line between data engineering and AI engineering is dissolving.
AI assistants and AI-enhanced workflows are projected to reduce manual data engineering intervention by 60% by 2027, enabling a new class of self-service data management.
The most consequential development is the emergence of large language models as a foundational intelligence layer within data infrastructure. Specialized LLMs autonomously optimize database schemas, generate and maintain ETL pipelines, and perform predictive resource scaling. Domain-specific models (trained on healthcare terminology and HIPAA requirements, or on financial regulations and risk vocabularies) can deliver materially superior results compared to general-purpose models for schema inference, data quality rules, and compliance documentation.
At the same time, Gartner projects that by 2028, GenAI-powered narrative and visualization will replace more than half of existing dashboards, shifting the role of the data engineer toward curating the data products that AI systems consume and present.4. DataOps and MLOps
DataOps principles promote collaboration and automation between data engineering, data science, and IT teams. MLOps extends these principles to developing, deploying, and monitoring machine learning models.
By adopting DataOps and MLOps practices, organizations can streamline data pipelines, improve data quality, and ensure the smooth operation of data-driven applications.
Data engineering teams guided by mature DataOps practices can achieve 10x productivity gains compared to traditional approaches, as continuous feedback loops and agentic AI automation deliver end-to-end orchestration across the full data lifecycle.
The integration of DataOps and MLOps into unified frameworks has become a strategic priority. These frameworks reduce deployment friction, automate time-consuming procedures, and support distributed, multi-cloud architectures. A key development as for 2026 is the rise of DataGovOps – governance as code – in which compliance procedures, audit trails, and data lineage tracking are automated through integrated background processes rather than manual oversight.
The integration of DataOps and MLOps into unified frameworks has become a strategic priority. These frameworks reduce deployment friction, automate time-consuming procedures, and support distributed, multi-cloud architectures. A key development as for 2026 is the rise of DataGovOps – governance as code – in which compliance procedures, audit trails, and data lineage tracking are automated through integrated background processes rather than manual oversight.
5. Data governance and privacy
Once a compliance function managed by a small team with spreadsheets, data governance is now a first-class engineering concern embedded throughout the data stack. The regulatory environment is more demanding than ever, and the response must keep pace with that demand through automation.
GDPR enforcement actions reached record levels in 2023-2024, and the EU AI Act (which entered into force in August 2024) imposes new requirements for transparency, explainability, and data lineage on AI systems. In parallel, data observability platforms are evolving to merge governance, performance monitoring, and security into unified systems.
50% of organizations with distributed data architectures are expected to adopt sophisticated observability platforms in 2026, up from under 20% in 2024. These platforms provide automated GDPR compliance validation, real-time lineage tracking, and centralized policy enforcement with audit trails generated automatically.
Synthetic data has also emerged as a governance-enabling technology. Rather than anonymizing real data – a process with well-documented re-identification risks – organizations are generating statistically representative synthetic datasets for analytics, AI training, and testing.
6. Serverless data engineering
Serverless architectures eliminate the need for data engineers to manage and maintain servers. This allows them to focus on data pipelines and data modeling while the cloud provider handles server provisioning, scaling, and maintenance. This not only simplifies data engineering but also reduces operational costs.
The global serverless architecture market is expected to reach USD 59.0 billion by 2033, with data processing workloads among the primary drivers of growth. AWS Lambda, Google Cloud Functions, Azure Functions, and their data-specific counterparts (AWS Glue, Google Dataflow, Azure Data Factory) have matured considerably, with improved cold-start performance, larger memory ceilings, and tighter integrations with streaming and orchestration tools.
A significant development is also the serverless data warehouse and lakehouse – platforms like Snowflake and BigQuery that expose a fully serverless consumption model, charging only for query compute and storage. This model is driving adoption among mid-market organizations that previously lacked the engineering capacity to manage dedicated data infrastructure.
A significant development is also the serverless data warehouse and lakehouse – platforms like Snowflake and BigQuery that expose a fully serverless consumption model, charging only for query compute and storage. This model is driving adoption among mid-market organizations that previously lacked the engineering capacity to manage dedicated data infrastructure.
7. Evolution of data lakes
The pure data lake has given way to more sophisticated architectures. Now, the dominant evolution is the data lakehouse : a unified platform that combines the low-cost, flexible storage of a data lake with the ACID transactions, schema enforcement, and query performance traditionally associated with data warehouses.
Open table formats have been the technical catalyst for this evolution. Apache Iceberg, Delta Lake, and Apache Hudi enable data lake storage to support ACID transactions, time-travel queries, schema evolution, and efficient metadata management. These formats have achieved near-universal adoption among leading data platforms, with Iceberg emerging as a particularly strong open standard that enables interoperability across engines including Spark, Flink, Trino, and Snowflake.
The next evolution beyond the lakehouse is the data lakehouse with live tables – real-time materialized views and streaming tables that keep analytical results current without full query re-execution.
8. Big data and IoT
The Internet of Things continues to expand, with the number of connected devices expected to exceed USD 39 billion by 2035. Each device is a potential data source, and the aggregate volume, velocity, and variety of IoT data present both opportunities and formidable engineering challenges.
A significant architectural shift is the movement of processing closer to data sources – edge computing . Rather than transmitting all IoT data to a centralized cloud infrastructure, edge nodes perform initial filtering, aggregation, and inference locally, transmitting only high-value or anomalous data upstream.
A significant architectural shift is the movement of processing closer to data sources – edge computing . Rather than transmitting all IoT data to a centralized cloud infrastructure, edge nodes perform initial filtering, aggregation, and inference locally, transmitting only high-value or anomalous data upstream.
This reduces bandwidth costs, latency, and the attack surface for sensitive operational data. AWS Greengrass, Azure IoT Edge, and Google Distributed Cloud Edge are the leading platforms for this pattern.
The engineering challenge is not just volume management – it is semantic interoperability. IoT deployments involve heterogeneous devices, protocols (MQTT, OPC-UA, Modbus), and data schemas. Knowledge graphs and semantic layers are increasingly being used to create unified representations of IoT data that enable cross-device analytics without brittle schema mappings.
The engineering challenge is not just volume management – it is semantic interoperability. IoT deployments involve heterogeneous devices, protocols (MQTT, OPC-UA, Modbus), and data schemas. Knowledge graphs and semantic layers are increasingly being used to create unified representations of IoT data that enable cross-device analytics without brittle schema mappings.
9. Data mesh
The data mesh architecture proposes a decentralized approach to data ownership and management. It breaks down data into domains managed by individual teams, promoting agility and scalability in complex data landscapes. This architecture is particularly well-suited for large organizations with diverse data needs.
The four core principles of data mesh – domain ownership, data as a product, self-serve data infrastructure, and federated computational governance – require significant organizational and technical change. This is where many implementations have struggled: the technology is tractable, but changing data ownership culture in large enterprises is slow and politically complex.
Gartner notes that data mesh, combined with composable platform architectures and federated API-first design, is becoming the standard for resilient, transparent, and democratized enterprise data management. However, they also caution that organizations should expect multi-year implementation timelines and invest heavily in change management alongside technical implementation.
10. Data quality and data integration
As the number of data sources continues to diversify, ensuring data quality and seamless integration becomes increasingly critical.
Poor data quality is estimated to cost organizations an average of USD 15 million per year , and the problem compounds as AI systems consume low-quality data to produce unreliable outputs.
So, the technical response has evolved beyond rule-based validation toward AI-powered quality monitoring: systems that learn expected data distributions, detect drift, identify outliers, and autonomously surface the root causes of quality failures.
Data observability platforms now provide end-to-end pipeline health monitoring that surfaces quality issues before they reach downstream consumers. This represents a significant maturation from the previous generation of point-in-time data quality tools.
Poor data quality is estimated to cost organizations an average of USD 15 million per year , and the problem compounds as AI systems consume low-quality data to produce unreliable outputs.
So, the technical response has evolved beyond rule-based validation toward AI-powered quality monitoring: systems that learn expected data distributions, detect drift, identify outliers, and autonomously surface the root causes of quality failures.
Data observability platforms now provide end-to-end pipeline health monitoring that surfaces quality issues before they reach downstream consumers. This represents a significant maturation from the previous generation of point-in-time data quality tools.
On the integration side, the emergence of data contracts as an engineering practice is reshaping how data producers and consumers coordinate. A data contract is a formal, versioned agreement that specifies the schema, quality expectations, update frequency, and SLAs for a dataset. When upstream producers change their data, contracts provide a mechanism for detecting breaking changes before they propagate downstream.
Lift your business to new heights with Binariks' AI, ML, and Data Science services
Prospects of data engineering for 2026-2028
The big data market is expected to reach USD 862 billion by 2030. Companies worldwide should be digging and biting into this pile of data to find what makes their business grow, evolve, and stay competitive. "Data Engineer" remained one of the fastest-growing jobs in 2025.
Here are some key facts and statistics to know about the prospects of data engineering:
- The salary for a data engineer in the United States ranges between USD 90,000 and USD 220,000+ (junior-level position vs. senior roles)
- Proficiency in SQL, Python, and Java and tools like Apache, Hadoop, and Spark are essential for data engineers. These technologies are fundamental for efficiently managing, processing, and analyzing large datasets.
- Many data engineers hold degrees in computer science or related fields. Additionally, certifications in data engineering can significantly enhance career prospects by validating expertise and commitment to the field.
- The data engineering field is expected to continue growing rapidly as businesses increasingly rely on data-driven decision-making to remain competitive. This trend underscores the ongoing need for skilled data engineers.
- In the future, data engineers must collaborate more closely with data scientists and analysts. This collaboration will support advanced analytics and AI projects, necessitating a deeper understanding of these areas.
- As technology evolves, continuous skill updates will be crucial for data engineers. Staying current with advancements in cloud computing , machine learning, and new data processing frameworks will be essential to maintain relevance in the field.
- There will be a move towards hybrid data architectures, combining on-premise and cloud solutions. This approach will cater to diverse business needs and offer flexibility and scalability.
- Sustainability will become a focal point, with a growing emphasis on building energy-efficient data processing systems. This shift aims to reduce the environmental impact of large-scale data operations, aligning with broader corporate sustainability goals.
"Making well-informed decisions is something that companies should be doing no matter what stage they are in, and data is an important input for making decisions. With affordable and easy to adopt tools which include cloud warehouses, ETL tools, event management tools, and BI tools, there’s no reason a company shouldn’t have a proper data stack setup to inform their decision-making processes."
Andrew McEwen, Co-founder at Secoda
"I do not see it so much as an evolution but as an increased understanding of value. Maybe that is the same thing as evolution, but I truly think the true role of the Data Engineer is enablement. The adoption of modern data stack technologies and this wonderful mix of build and buy available tooling makes the role less about writing pipelines and being a data warehouse DBA. It is more about enabling secure, reliable data access across the organization."
Braun Reyes, Data Engineer at Clearcover
To sum it all up, looking towards 2026-2028 data engineering industry trends, its importance will only magnify. Trends like data democratization will see more users across organizations needing data access. Here, data engineers will be instrumental in creating user-friendly interfaces and tools to empower this broader data utilization.
Additionally, the ever-evolving regulatory landscape surrounding data privacy demands data engineers to stay updated on compliance and build robust data governance practices. Finally, data engineering plays a critical role in the rise of automation. Data engineers will be at the forefront of this transformative trend by creating and maintaining data pipelines that feed machine learning models and AI applications.
Unlock your data's potential: discover Binariks' Big Data and analytics services today!
Harness comprehensive data engineering solutions
The forecasts for data engineering are brimming with exciting possibilities. However, implementing these cutting-edge trends and technologies requires a well-defined strategy and expert execution. While the potential of data engineering solutions is undeniable, they are most effective when carefully designed, configured, and integrated into your existing data infrastructure.
And this is where Binariks can help. Our data specialists will work collaboratively with your team to understand your unique needs and challenges.
By leveraging our experience and industry best practices, we can design and implement a data engineering solution that is:
- Scalable: Adapts to accommodate your growing data volumes and evolving needs.
- Secure: Protects your sensitive data with robust security measures.
- Efficient: Streamlines data pipelines for faster processing and analysis.
- Cost-effective: Optimizes your data infrastructure to maximize value.
As data continues to be the lifeblood of business success, organizations that embrace innovative data engineering practices will gain a significant edge. Contact Binariks if you're looking for a reliable tech partner to unlock the full potential of your data and propel your business forward.
Author

Share